Anand Sukumaran
Software engineer focused on backend systems, infrastructure, and product engineering.
Co-founder & CTO @ Engagespot (Techstars NYC '24)
Why do LLMs fail to count letters in a word?
Mar 06, 2025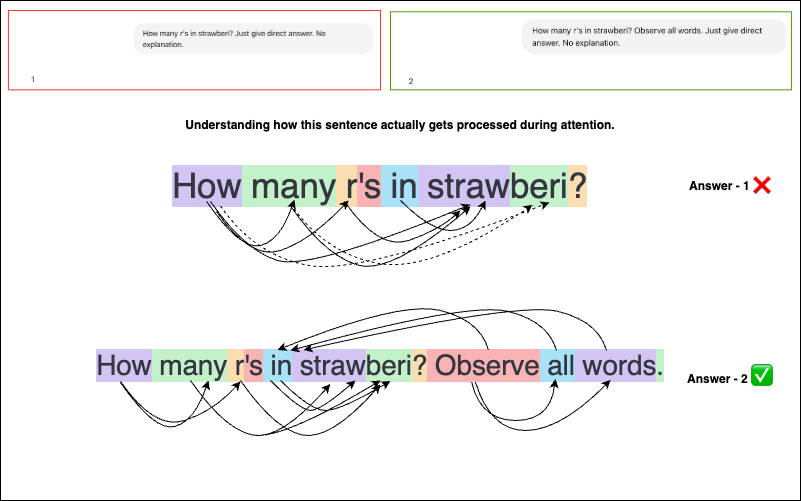
Why do LLMs fail to count letters in a word? Here’s an easy way to understand. But let’s NOT do the famous “strawberry” test.
Because, most LLMs now answer that correctly (memorised it probably?). Instead, use a slightly misspelled word - “strawberi” or “strayberi,” etc.
Asking “How many r’s in strawberi?” will give 1 instead of 2. Let’s understand why.
The first thing to understand is that LLMs don’t see words. They see sub-words (tokens) based on how they are trained.
For example, an LLM might see “strawberry” as a single word, but according to OpenAI’s tokenizer, “strawberi”, the misspelled word is split into two tokens: “straw” and “beri”.
Ok, Let’s ask the famous question: “How many r’s in strawberry?”
The attention mechanism is giving focus to words “how”, “many”, “r”, “strawberry” which might be well known to the neural network, leading to higher confidence for predicting 3. (This could be considered as equivalent to human memorising an answer without thinking)
But when we ask: “How many r’s in strawberi?” (the misspelled word)
The attention might now be focused on “straw”, not “strawberi”. Why? Because “strawberi” is split into two tokens, so the model might be considering the tokens as -
“How”, “many” “r” “‘s” “in” “straw” “beri”. Thus it is probably trying to predict the next token by giving more attention to all tokens, except beri as “beri” doesn’t seem to be associated. This leads to a less confident next token probability, which ends up as 1 or 0 (depending on how the count of r in token - “straw” is guessed by the LLM). -> One important thing to note here is that, the LLM still cannot “count”.
Now, let’s try another variation:
“How many r’s in strawberi? Count the word after ‘straw’ as well.” This time, the model correctly responds 2.
Why? I’m not sure of the exact reason, but it’s likely because we shifted attention from “straw” to “straw” + “beri” together, by including few other words.
A similar result happens with: “How many r’s in the sentence ‘strawberi’?” → It responds 2.
In this example as well, we’re shifting the probabilty of next token prediction to consider both “straw” and “beri”.
We see “strawberi” as a single word, but LLMs see it as “straw” + “beri”, or “str” + “awb” + “eri” depending on tokenization and how the attention mechanism is learned to associate tokens.
Many similar examples shows that tokenization is “one of the causes” behind this behavior in LLMs.
However, If you allow the model to “think” by writing each letter, and writing something like found 1r, 2r etc, it will most likely result in a correct answer. This is what we call “thinking”, and that’s a different story.
Another experiment:
I provided an image of the question instead of typing it, and the model is now getting the answer right, for most of the samples. Why? Likely because it doesn’t go through the same sub-word tokenization process. In this case, each letter might have got individual attention.