Anand Sukumaran
Software engineer focused on backend systems, infrastructure, and product engineering.
Co-founder & CTO @ Engagespot (Techstars NYC '24)
LLMs can understand. They are not just next token predictors
Mar 09, 2025Do LLMs “understand” what they are saying? Yes, they do. They are not just simple next-token predictors!
If you want a true next-token predictor, look at how a Markov chain works. Its behavior is predictable. But LLMs are not.
Why? Because LLMs do not process words, tokens, or characters individually. They process their “understandings.” How?
In an LLM, every word (or token) is represented as a high-dimensional vector with thousands of features. For example, when it processes the word “cat,” it is not processing the word “cat”. Instead, it operates on the properties of “cat” such as -> cat is an animal, not an object. It is small in size, unlike an elephant. It is carnivorous, not like a cow.
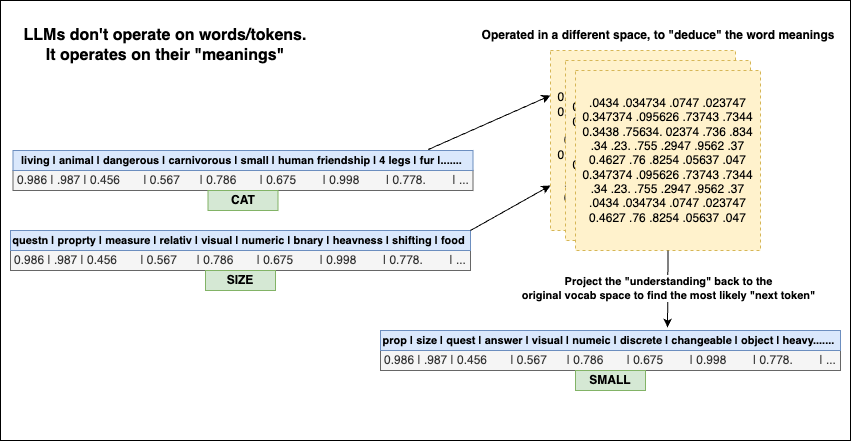
And it uses these properties of the word “cat” to predict the “next” things.
An LLM learns thousands of properties about the word “cat” and understands how those details relate to other words. How did it “learn” these facts?
Before answering that, ask this: “How do humans learn these facts?”
We learn by observing, reading, and hearing about a cat’s characteristics. Our brains process this input from our senses and associate it with things we already know.
For example, when we hear “it has four legs,” our brain immediately connects it to “other things” with four legs. This helps us place the word “cat” in our mental “embedding space.”
As we get more information, our understanding may shift and improves.
And when we hear “a cat jumped from our terrace” - We are not processing the words, we’re processing their properties. We know what happens when things with weight fall, and we know cat has weight. Hence we “deduce” the next thing.
LLMs do something similar. But they have only one sense - words (tokens). Their entire world is made up of words, created by humans from trillions of books and documents. So they develop a deep understanding of that world.
Every time an LLM reads about a “cat” during training, it learns from the context in which the word appears. For example, if it sees the sentence “The cat jumped across the wall,” it doesn’t just memorize these words together. Instead, it learns that:
A small object (like a cat) is associated with jumping.
So, next time it encounters another small object, like a matchbox, it might assume it can also jump. But over time, the LLM refines this idea and learns that “small” alone isn’t enough for jumping. Instead, a living property (like being an animal), “legs” etc is also necessary.
This happens across thousands of such associations.
This ability to “think” doesn’t appear at small scales. It only emerges when models reach vast scales - associating thousands of properties for each token across trillions of tokens.
A deeper explanation is beyond the scope of this post.
So, LLMs don’t just associate words because they appear together in a sentence. Instead, they learn thousands of properties for each word and use those properties to “think” and make connections.