Anand Sukumaran
Software engineer focused on backend systems, infrastructure, and product engineering.
Co-founder & CTO @ Engagespot (Techstars NYC '24)
Here's an interesting experiment I did to understand how LLMs do math
Mar 24, 2025Here’s an interesting experiment I did to understand how LLMs do math ✨
For simple math problems, like 2 + 2 = ?, the model answers correctly because it has seen that exact question countless times during training. In fact, it might have memorized “2 + 2 = 4” along with other basic calculations.
But when it comes to a problem it likely hasn’t seen during training - for example, 9183742 × 47489 = ? - it just fails!
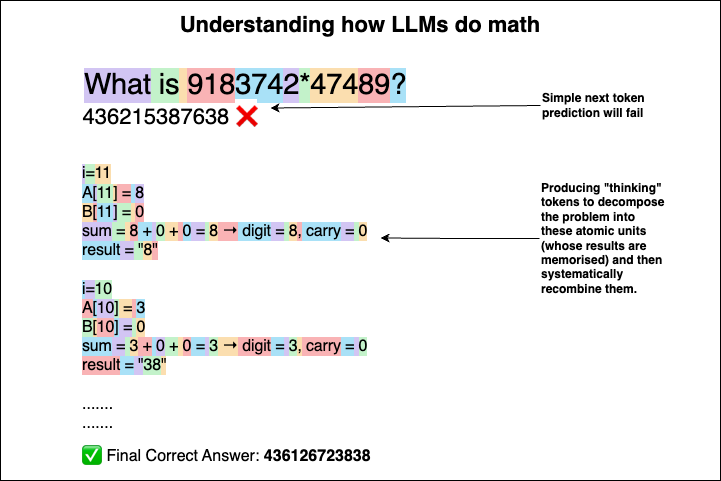
I asked GPT-4o: “What is 9183742 × 47489?”
It answered: “436215387638” - which is wrong ❌
Why does this happen?
It hasn’t seen this specific example during training - no memorization.
The answer can’t be deduced through simple next-token prediction (even humans can’t do that instantly).
So how do humans solve complex math?
Because we were trained in school to write down steps and solve problems step-by-step. We did this so many times that we eventually learned the pattern. And for basic operations like 2 + 2, we either memorized them or used fingers or mental images to work them out when in doubt.
How should LLMs do math?
By decomposing the problem into atomic units (whose results are already memorised -> for eg: 2+2=4) and then recombine them.
So in theory, if we instruct LLMs to follow similar “steps”, they should be able to solve complex math too!
I tried this by prompting the LLM with the rules of multiplication.
Of course, it wrote out the steps correctly - but still ended up with the wrong final answer. I wanted to know why.
If you’re familiar with attention mechanisms, you can probably guess why: the more tokens it produces, the noisier its predictions get over time. And LLMs produce the output for human readability without realizing that the tokens they produce will guide them to get more clarity.
So I had an idea:
Since LLMs are fine-tuned to produce responses that are visually appealing to humans (Like with spacing, code blocks and all), I gave it a different instruction: “Write steps for your own internal understanding, - not for humans.”
And suddenly, the steps looked different - more like a raw algorithm than a polished explanation.
Why? Because I taught the LLM to think for itself, for helping it’s attention mechanism to make better predictions. Not to impress us.
This time, it got the correct answer: 436126723838 ✅
We often think of LLMs as mere next-token predictors - and oversimplify things like chain-of-thought as just a trick. But it’s more than that.
In a strange way, it thinks like we do - by producing tokens to observe patterns in it’s latent space, just as we form mental images or silent steps while thinking.
If LLMs are taught how to “think” for themselves, they might produce better results - and even use fewer tokens.