Anand Sukumaran
Software engineer focused on backend systems, infrastructure, and product engineering.
Co-founder & CTO @ Engagespot (Techstars NYC '24)
How HTTP/3 works? Why it was needed? What's wrong with HTTP/2.0 and HTTP/1.1
May 14, 2023As you might have heard, HTTP/3 is the latest revision of the HTTP protocol that’s published as a proposed standard in June 2022. Around 26% of the world’s website traffic is now through this new, fast protocol. Almost all browsers supports HTTP/3 except Safari which is known to be slow in adopting new features.
For the last few weeks, I’ve been trying to understand this protocol. It was really interesting to go back to the core networking concepts, and the OSI layers to understand how things work under the hood.
In this blog, I’ll explain how HTTP/3 works, and why it was needed! The purpose of this article is to explain the concepts in basic terms so it could be understood by people without strong understanding of networking concepts.
Why HTTP3 was needed?
Well, to answer this question, it is essential to have an understanding of it’s predecessors HTTP/2.0, HTTP/1.1 and HTTP/1.0 and their limitations. It may not be ideal to discuss all of them in detail on this blog. But let me try to be as brief as possible.
A quick explanation of TCP before we start
Well, as you might know, HTTP is an application layer protocol that uses TCP to transport the data. TCP protocol is essentially what makes communication possible between multiple applications in two computers connected over a network.
Consider TCP as a set of rules that was designed to carry packets of data (chunks of an HTML or CSS file, image, Javascript etc) over the cables connected between two computers.
A TCP packet only knows that it is carrying some bytes of data from a source to a destination application, identified by the computer’s IP and the application port address.

TCP is connection oriented which means a connection has to be established between the source and destination via a handshake process. Just keep in mind that opening a TCP connection is a complex (and expensive) process for the operating system kernel as it needs to maintain a separate memory table for every connection, then do all these handshakes (with even more added complexity in case of HTTPS because of TLS).
Also TCP ensure ordered packets. That means, in a network where multiple TCP packets are being sent with sequence numbers 1,2,3…, if one packet didn’t reach the destination, all other packets will wait for the missing packet to be retransmitted from the source.
So, just remember that TCP carries bytes of data packets and it doesn’t know what we’re transporting. And also that one packet loss affects all other packets in the sequence.
How HTTP uses TCP to transport requests and responses
HTTP is a plain text protocol that specifies how a resource (such as an HTML file) should be transported. It uses a HEADER to identify the resource and a BODY for it’s content.
Let’s say the browser requested for GET /index.html file. This is how the server responds in the HTTP/1.1 format.
HTTP/1.1 200 OK
Last-Modified: Thu, 09 Jan 2014 21:28:13 GMT
ETag: "434-4ef90496c3540"
Accept-Ranges: bytes
Content-Length: 1076
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html lang="en" xml:lang="en">
<head>
<title>Hello World</title>
</head>
</html>
(Figure 1 - Sample HTTP/1.1 response to send index.html)
This is entirely plain text as you can see. Simple to understand! It has a header, and a body that includes the entire index.html file. The browser just needs to parse this HTML file and render it to the user.
But how is this response transported from the server to your browser? Well, the server splits this HTTP response into multiple TCP packets and send it your computer’s IP address in an ordered sequence. It’s the job of your operating system to receive those TCP packets in the sequential order assemble them together, re-construct this HTTP response and pass it to the browser so it can render the beautiful index.html page.
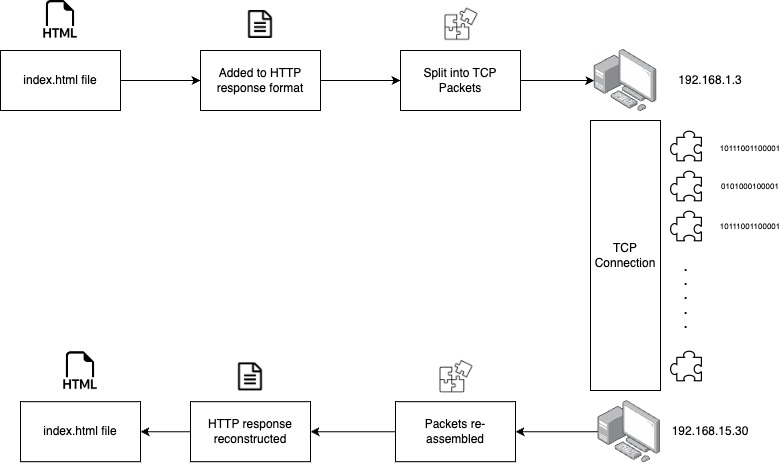
That’s all you need to know about the basic working of HTTP protocol for the purpose of understanding this blog (:D).
HTTP 1.1
HTTP 1.1 was introduced in 1997 when the internet was so different from today. Unlike today’s rich media types such as videos, high quality images, binaries etc websites at that time were mostly built using text, and basic images. In short, fewer files needs to be transported to render a website.
Let’s look at how HTTP/1.1 responses were sent through TCP.
The client (browser) opens a TCP connection with the web server and requests for the index.html file. The server then constructs the TCP packets for the HTTP response given in Figure 1, and sends them to the browser.
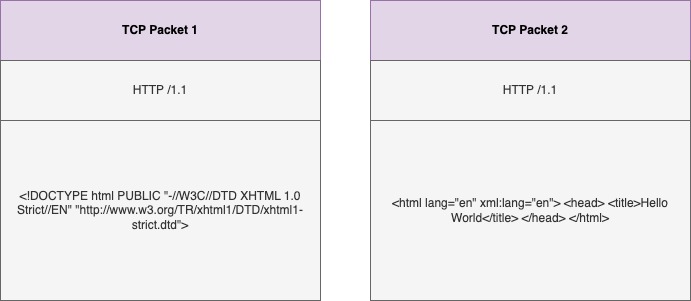
But there is a problem. A website will have other files like stylesheets and images, not just an index.html file. Since we have opened only one TCP connection between the client and server, it can transport only 1 file at a time, and per TCP connection. Once the index.html file packets have been transported, that TCP connection is closed and another connection is opened to transfer the next file. (Well, I’m ignoring the keep-alive feature just for the sake of simple explanation).
Remember what we discussed before? Opening a TCP connection is complex and slow! And thus the process of opening multiple TCP connections for transferring all our website files results in slow rendering of our website. (Well, we are talking about latency in the order of milliseconds but several milliseconds adds up to seconds quickly!)
To solve this issue, browsers typically open 6 TCP connections per origin and thus it can transport 6 files in parellel without waiting. But today’s websites contain more than 6 files and thus there will be a wait no matter how.
Even if a connection is re-used (in the case of keep-alive), files arrive only one after another and they cannot be multiplexed. So one large or slow file can slowdown all other files to be transferred in the same connection.
HTTP 2.0
Now you know why HTTP/2.0 was needed. Yes, the inability to transport multiple files simultaneously in a single TCP connection was a waste of resources and network capacity. Well, with HTTP/2.0 that problem was solved by using the concept of multiple streams inside a single TCP packet.
In simple terms, HTTP/2.0 made it possible to transport pieces of more than one file in a single TCP packet.
Let’s say we have to transport two files to render our website. One is the index.html file mentioned in Figure 1 HTTP response. And another file style.css as shown below.
body {
margin: 25px;
background-color: rgb(240,240,240);
font-family: arial, sans-serif;
font-size: 14px;
}
h1 {
font-size: 35px;
font-weight: normal;
margin-top: 5px;
}
Figure 2 - Sample style.css file
Instead of sending one file per TCP packet, we can now send pieces of more than 1 file per packet.
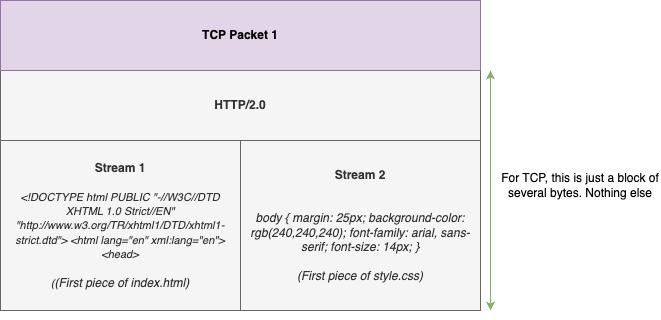
Think of the advantage this gives. If the style.css was a smaller file, it would have been transported completely with the 3rd or 4th packet, where are the index.html file might need few more packets.
Thus it solves a major problem in networking called the Head of Line Blocking, by using multiple binary streams within a TCP packet.
Then Why HTTP/3 was needed?
If HTTP/2.0 solved the head of line blocking issue, then what was the need for another revision? That’s a good question.
You know we’re using TCP for both HTTP/1.1 and HTTP/2.0. And we solved the head of line blocking using streams in the latter. Guess what? It solved the problem only at the HTTP layer. The HOL blocking issue still exists in the TCP layer!
I’ll explain.
As we know, TCP is a reliable form of communication that re-transmits missing packages. Remember what we discussed? TCP packets are assembled only upon receiving all the packets in a sequence! This is a huge bottleneck for our HTTP communication.
Let’s say we’re using HTTP/2.0 streams to transport two files (index.html and banner.jpg). Assume that 5 TCP packets are needed to transport them completely. With the successful transport of packets 1,2,4 and 5, the index.html might have been transferred completely. However, the banner.jpg might be complete only after receiving packets number 3 that went missing. The problem with TCP here is that, it waits until the missing 3rd packet is received to transfer the files to browser. You know that the browser could have started parsing the html file even without the 3rd packet but TCP makes it impossible!
So, as you might have guessed, TCP is the problem! So yes, the decision was to move to UDP, but UDP is unreliable because of the way it is designed. It won’t guarantee the delivery of packets, there is no guarantee of ordered delivery and it won’t retransmit them in case one packet goes missing!
The need for QUIC
How can we use an unreliable protocol? Well, that’s why another protocol called QUIC(Quick UDP Internet Connections) was implemented on top of UDP to make it reliable for our purpose!
With QUIC, streams are supported at the transport layer itself and therefore no need for HTTP to implement them. Remember, TCP had no information about the multiple streams being transported because all it sees is a large block of bytes, nothing else!
But with QUIC, it knows that multiple streams are being transported in a packet, and they needs to be treated independently.
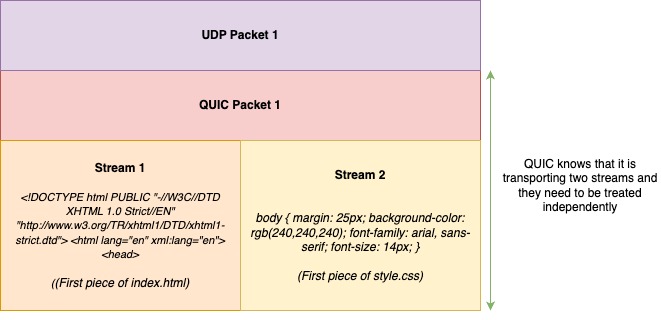
Unlike in TCP, QUIC retains ordering within a stream and not across the packet. (Thanks to UDP that made no rule to make it’s packets sequential).
So yea, that was the primary goal, to avoid TCP head of line blocking issue in transporting website data!
Current State of HTTP/3
HTTP/3 is a proposed standard by IETF and is being widely adopted. HTTP/3 by default makes TLS mandatory. HTTP/3 can be incredible faster along with 0-RTT (Zero Round Trip Time). Because with HTTP over TLS 1.3, it takes 3 round trips from client to server to establish a connection and start sending the data.
Currently HTTP/3 is -
- Around 25-26% of the web traffic now uses HTTP/3
- Supported by all major browsers except Safari.
- Over 3.5x faster to load a single page application, compared to HTTP/1.1
However, availability of client libraries are still a challenge for developers. I’ve tried to compile the list of few libraries.
| Language | Library |
|---|---|
| Python | aioquic |
| Nodejs | In discussion? |
| Java | KWIK |
| Go | quic-go |
| Rust | quiche |
| C, C++ | mvfst |
| Ruby | None? |
Hope you’ve understood the basic concepts of HTTP/3 and how it uses QUIC protocol to solve the problems existed in TCP protocol.