Anand Sukumaran
Software engineer focused on backend systems, infrastructure, and product engineering.
Co-founder & CTO @ Engagespot (Techstars NYC '24)
Understanding Agentic Context Engineering (ACE) - Self-improving LLMs without fine-tuning
Oct 12, 2025I recently read a new research paper published by Stanford, SambaNova, and UC Berkeley that proposes a better way to improve the agentic performance of LLMs - without updating their weights (fine-tuning). The method is called Agentic Context Engineering (ACE). In this post, I’ll try to explain what ACE is in simple terms.
Prompt engineering is something we’re all familiar with - writing well-crafted prompts to guide an LLM in performing specific tasks. But this is a static method and has largely been replaced by dynamic prompting (or prompt-updation) strategies, especially in the agentic world. These approaches improve prompts through feedback loops - observing results and refining prompts accordingly. Strategies like GEPA, Dynamic Cheatsheet, and others fall under this umbrella, collectively known as Context Adaptation Methods.
What was still unsolved (the problem!)?
Even though many context adaptation methods exist, they all share some key limitations - mainly Brevity Bias, the tendency for optimization to collapse toward short, generic prompts. These methods often use a monolithic prompt rewriting strategy. Whenever errors appear, GEPA tries to learn from the results and produce a new prompt. But over time, this approach consolidates the original details, compressing them into shorter, less specific versions. Instead of improving performance, this “compression” erodes context and leads to degradation.
This phenomenon is called Context Collapse. As context grows larger, the model tends to summarize it into much shorter, less informative versions - causing a dramatic loss of information.
At a simpler level, we could say LLMs suffer from a kind of amnesia: they forget or ignore instructions along the way. Humans do the same - we can’t rely solely on memory to perform complex tasks. That’s why we use playbooks or checklists, even for familiar routines. For example, pilots and co-pilots follow detailed checklists before every flight, despite having flown thousands of hours in their careers.
How Agentic Context Engineering helps
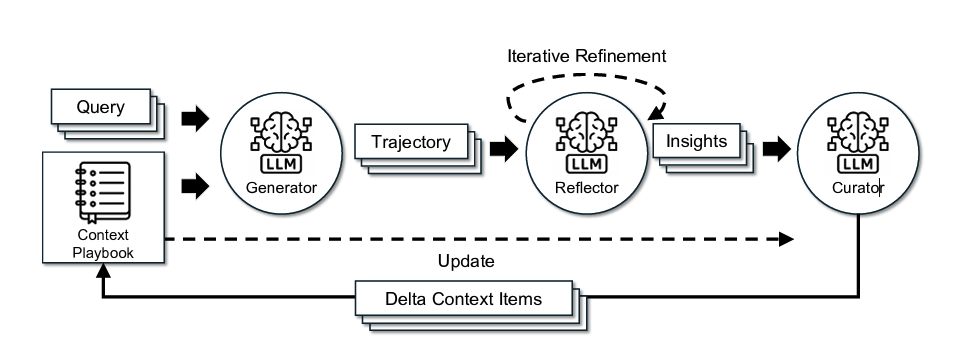
ACE introduces a modular workflow with three interconnected components, linked through an evolving, dynamic context playbook:
- Generator: Produces reasoning trajectories by observing the original query and context playbook.
- Reflector: Distills useful insights from the execution result by observing success or failure.
- Curator: Integrates these insights into the context playbook as incremental delta updates (not full rewrites).
Incremental data updates
A core design principle of ACE is incremental updates. Instead of rewriting the entire prompt, ACE adds small delta updates to the context playbook.
Each update has two parts:
- Metadata - includes a unique ID and counters that track how often this insight was marked helpful or harmful.
- Content - the actual helpful instruction or learning.
And the results?
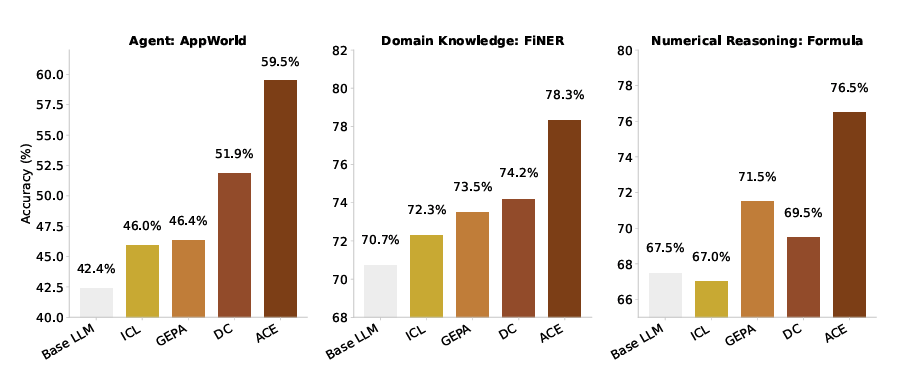
According to the research paper, ACE improves accuracy on the AppWorld benchmark by up to 17.1%, purely from execution feedback - no ground-truth labels required. It also allows smaller models to match the performance of top proprietary agents (like GPT-4) on the leaderboard.
On complex financial reasoning tasks, ACE delivers an average performance gain of 8.6%.
Even with all three components (Generator, Reflector, Curator) working together, ACE remains efficient - reducing latency by 86.9% on average and cutting token costs compared to other context adaptation strategies.
My thoughts
I’m always exploring strategies that tackle common LLM problems like hallucination and failure to follow instructions - and I often compare how humans handle these challenges. Every time, it leads to the same insight: humans aren’t perfect either.
It’s not just the weights that lead to better results, but the workflow - iterative planning, learning from experience, and reapplying insights. It increasingly seems that progress depends less on raw intelligence and more on the methods we apply.
Some people are great problem solvers not because they’re more intelligent, but because they’re experts at analyzing the root cause, extracting insights, and applying them next time. ACE is essentially trying to teach LLMs to do the same.